A las 3:47 PM de un martes, tu endpoint /api/payments empieza a devolver errores 500. La tasa de error sube del 2% al 15% en 20 minutos. A las 4:12 PM, un cliente tuitea sobre una compra fallida. A las 4:18 PM, tu equipo de soporte manda un mensaje en Slack: "Estamos teniendo problemas con pagos?"
Este no es un escenario raro. Es como la mayoria de equipos de APIs experimentan incidentes — reactivamente, caoticamente, y con un MTTD medido en quejas de clientes.
Las dos metricas que importan: MTTD y MTTR
MTTD (Mean Time to Detect): El tiempo entre cuando empieza el incidente y cuando tu equipo se entera. MTTR (Mean Time to Resolve): El tiempo desde la deteccion hasta la resolucion completa. Reducir MTTD de 30 minutos a 30 segundos tiene mas impacto que reducir MTTR de 45 a 30 minutos.
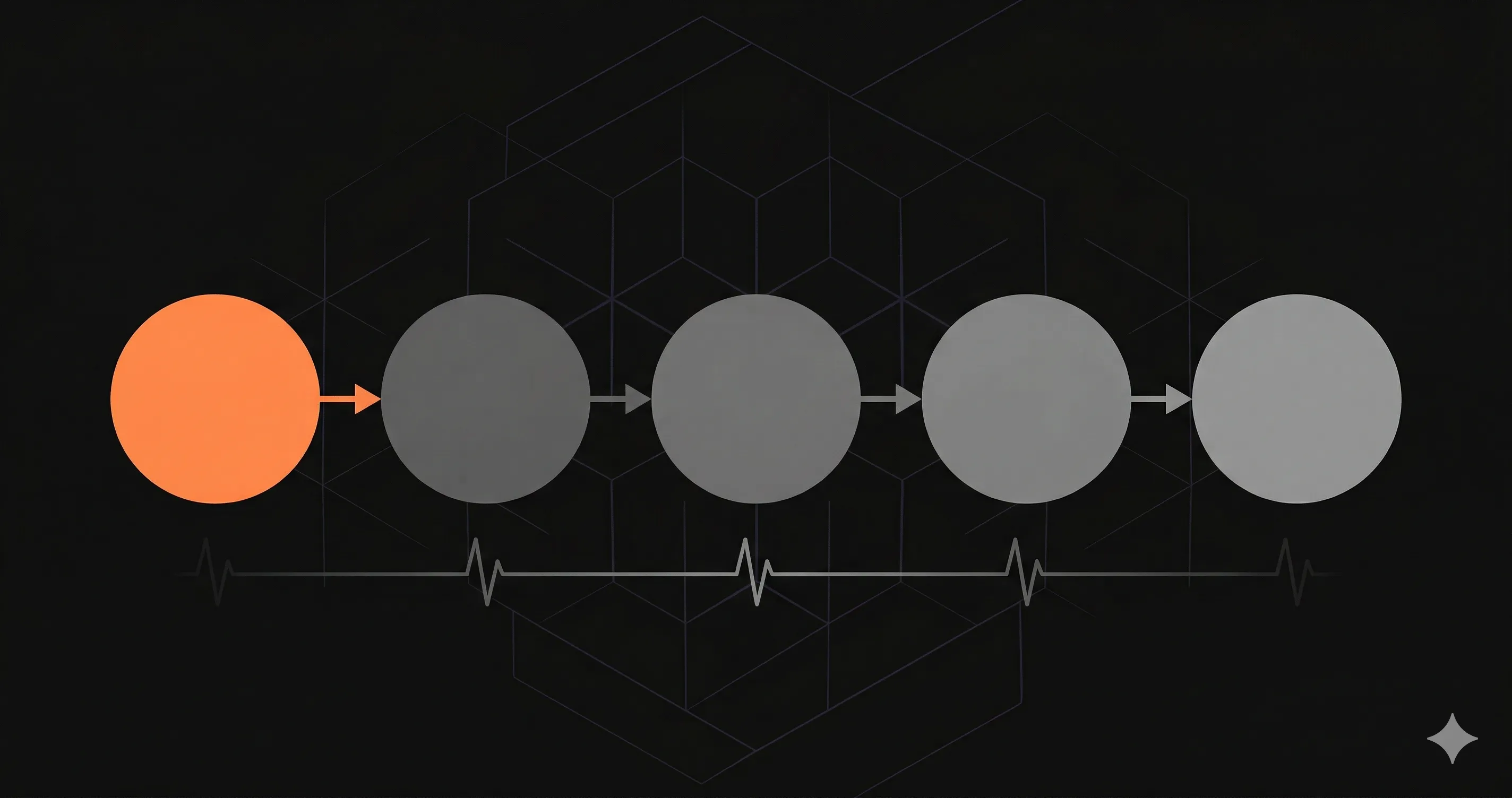
Los 5 pasos
1. Detectar: Monitoreo interno que trackea cada request es lo ideal. MTTD en segundos en vez de minutos.
2. Clasificar: En menos de 5 minutos, evaluar severidad. Cuales endpoints estan afectados? Cual es la tasa de error? Esta empeorando?
3. Mitigar: Parar el sangrado. Rollback, feature flags, escalar recursos, circuit breakers. No arreglar la causa raiz — reducir el impacto.
4. Resolver: El fix real. Correlacionar con cambios, revisar datos, reproducir, deployar el fix, verificar resolucion.
5. Aprender: Post-mortem blameless. Timeline, impacto, causa raiz, que salio bien, que salio mal, action items con duenos y fechas.
Reducir MTTD: la mejora de mayor impacto
Nurbak Watch reduce MTTD a segundos. Monitorea cada API route desde dentro del servidor via instrumentation.ts — 5 lineas de codigo — y envia alertas via Slack, email o WhatsApp en menos de 10 segundos. $29/mes (gratis durante la beta).